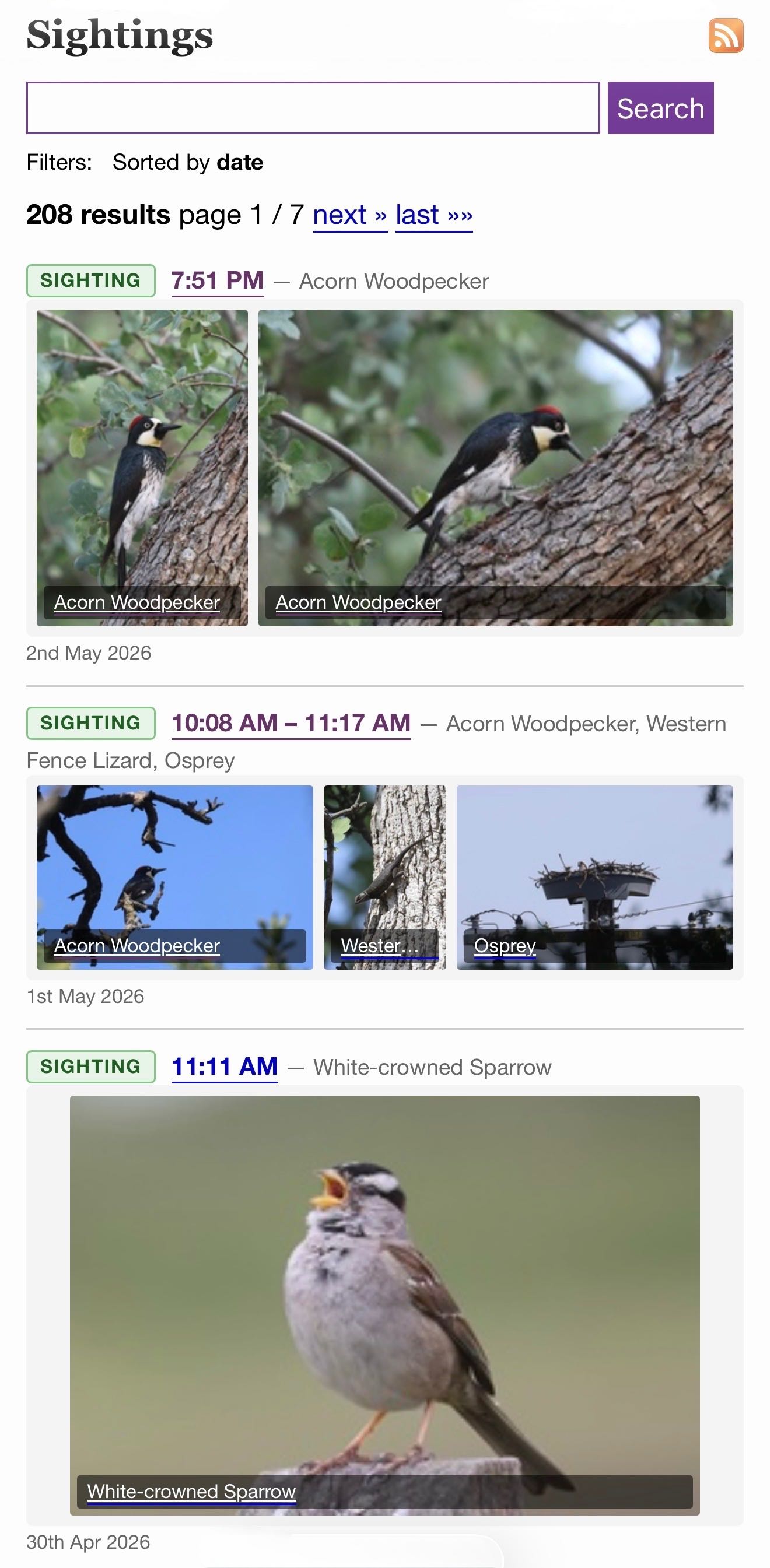
/elsewhere/sightings/
I have a new camera (a Canon R6 Mark II) so I'm taking a lot more photos of birds. I share my best wildlife photos on
iNaturalist, and based on yesterday's
successful prototype I decided to add those to my blog.
I built this feature on my phone using Claude Code for web, as an extension of my beats system for syndicating external content. Here's the PR and prompt.
As with my other forms of incoming syndicated content sightings show up on the homepage, the date archive pages, and in site search results.
I back-populated over a decade of iNaturalist sightings, which means you can search for lemur you'll see my lemur photos from Madagascar in 2019!
Tags: blogging, photography, wildlife, ai, inaturalist, generative-ai, llms, ai-assisted-programming, claude-code