You know what else we noticed in the interviews? Developers rarely mentioned “time saved” as the core benefit of working in this new way with agents. They were all about increasing ambition. We believe that means that we should update how we talk about (and measure) success when using these tools, and we should expect that after the initial efficiency gains our focus will be on raising the ceiling of the work and outcomes we can accomplish, which is a very different way of interpreting tool investments.
When a Jira Ticket Can Steal Your Secrets
Zenity Labs describe a classic lethal trifecta attack, this time against Cursor, MCP, Jira and Zendesk. They also have a short video demonstrating the issue.
Zendesk support emails are often connected to Jira, such that incoming supp...
I gave a talk on Wednesday at the Bay Area AI Security Meetup about prompt injection, the lethal trifecta and the challenges of securing systems that use MCP. It wasn't recorded but I've created an annotated presentation with my slides and detailed notes on everything I talk...
Hypothesis is now thread-safe
Hypothesis is a property-based testing library for Python. It lets you write tests like this one:
from hypothesis import given, strategies as st
@given(st.lists(st.integers()))
def test_matches_builtin(ls):
assert sorted(ls) == my_sort(ls)
...
I have a toddler. My biggest concern is that he doesn't eat rocks off the ground and you're talking to me about ChatGPT psychosis? Why do we even have that? Why did we invent a new form of insanity and then they charge people for it?
GPT-5 rollout updates:
We are going to double GPT-5 rate limits for ChatGPT Plus users as we finish rollout.
We will let Plus users choose to continue to use 4o. We will watch usage as we think about how long to offer legacy models for.
GPT-5 will seem smarter starting tod...
I've been dipping into the r/ChatGPT subreddit recently to see how people are reacting to the GPT-5 launch, and so far the vibes there are not good. This AMA thread with the OpenAI team is a great illustration of the single biggest complaint: a lot of people are very unhappy...
A couple of weeks ago I was invited to OpenAI's headquarters for a "preview event", for which I had to sign both an NDA and a video release waiver. I suspected it might relate to either GPT-5 or the OpenAI open weight models... and GPT-5 it was!
OpenAI had invited five developers: Claire Vo, Theo Browne, Ben Hylak, Shawn @swyx Wang, and myself. We were all given early access to the new models and asked to spend a couple of hours (of paid time) experimenting with them, while being filmed by a professional camera crew.
I've had preview access to the new GPT-5 model family for the past two weeks, and have been using GPT-5 as my daily-driver. It's my new favorite model. It's still an LLM - it's not a dramatic departure from what we've had before - but it rarely screws up and generally feels ...
I wrote about the Jules beta back in May. Google's version of the OpenAI Codex PR-submitting hosted coding tool graduated from beta today.
I'm mainly linking to this now because I like the new term they are using in this blog entry: Asynchronous coding agent. I like it so much I gave it a tag.
I continue to avoid the term "agent" as infuriatingly vague, but I can grudgingly accept it when accompanied by a prefix that clarifies the type of agent we are talking about. "Asynchronous coding agent" feels just about obvious enough to me to be useful.
Tom MacWright: Observable Notebooks 2.0
Observable announced Observable Notebooks 2.0 last week - the latest take on their JavaScript notebook technology, this time with an open file format and a brand new macOS desktop app.
Tom MacWright worked at Observable during their fi...
Yet another interesting model from Qwen—these are tiny compared to their other recent releases (just 4B parameters, 7.5GB on Hugging Face and even smaller when quantized) but with a 262,144 context length, which Qwen suggest is essential for all of those thinking tokens.
The new model somehow beats the significantly larger Qwen3-30B-A3B Thinking on the AIME25 and HMMT25 benchmarks, according to Qwen’s self-reported scores.
The easiest way to try it on a Mac is via LM Studio, who already have their own MLX quantized versions out in
gpt-oss-120b is the most intelligent American open weights model, comes behind DeepSeek R1 and Qwen3 235B in intelligence but offers efficiency benefits [...]
We’re seeing the 120B beat o3-mini but come in behind o4-mini and o3. The 120B is the most intelligent model that can be run on a single H100 and the 20B is the most intelligent model that can be run on a consumer GPU. [...]
While the larger gpt-oss-120b does not come in above DeepSeek R1 0528’s score of 59 or Qwen3 235B 2507s score of 64, it is notable that it is significantly smaller in both total and active parameters than both of those models.
No, AI is not Making Engineers 10x as Productive
Colton Voege on "curing your AI 10x engineer imposter syndrome".
There's a lot of rhetoric out there suggesting that if you can't 10x your productivity through tricks like running a dozen Claude Code instances at once you're f...
The long promised OpenAI open weight models are here, and they are very impressive. They're available under proper open source licenses - Apache 2.0 - and come in two sizes, 120B and 20B.
OpenAI's own benchmarks are eyebrow-raising - emphasis mine:
The gpt-oss-120b model ac...
Claude Opus 4.1
Surprise new model from Anthropic today - Claude Opus 4.1, which they describe as "a drop-in replacement for Opus 4".
My favorite thing about this model is the version number - treating this as a .1 version increment looks like it's an accurate depiction of t...
I teach HS Science in the south. I can only speak for my district, but a few teacher work days in the wave of enthusiasm I'm seeing for AI tools is overwhelming. We're getting district approved ads for AI tools by email, Admin and ICs are pushing it on us, and at least half...
I was exploring how ChatGPT agent works today. I learned some interesting things about how it exposes its identity through HTTP headers, then made a huge blunder in thinking it was leaking its URLs to Bingbot and Yandex... but it turned out that was a Cloudflare feature that...
This SVG tutorial by Josh Comeau is fantastic. It's filled with newt interactive illustrations - with a pleasing subtly "click" audio effect as you adjust their sliders - and provides a useful introduction to a bunch of well chosen SVG fundamentals.
I finally understand what all four numbers in the viewport="..." attribute are for!
ChatGPT agent is the recently released (and confusingly named) ChatGPT feature that provides browser automation combined with terminal access as a feature of ChatGPT - replacing their previous Operator research preview which is scheduled for deprecation on August 31st.
In e...
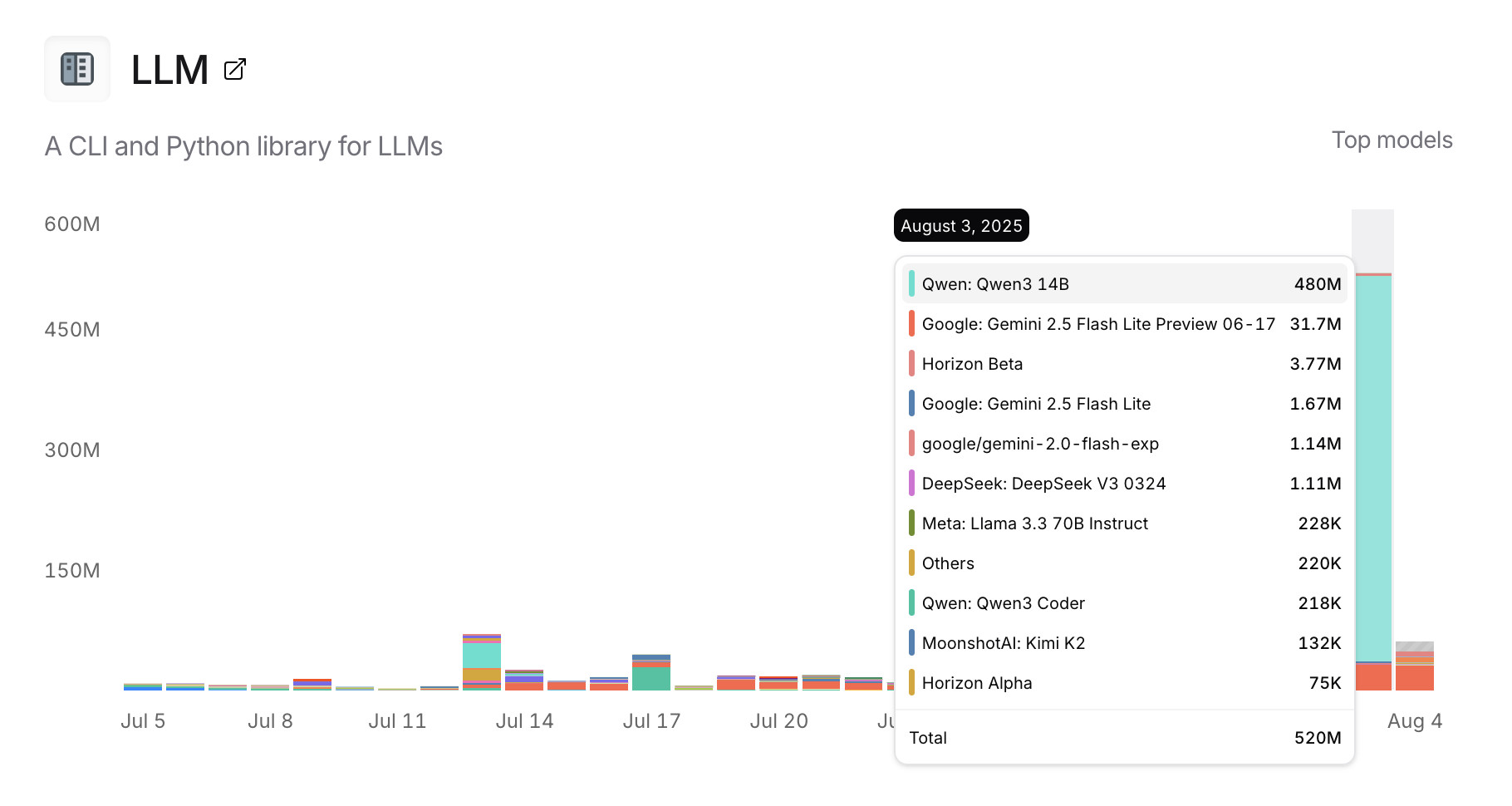
OpenRouter proxies requests to a large number of different LLMs and provides high level statistics of which models are the most popular among their users.
Tools that call OpenRouter can include HTTP-Referer and X-Title headers to credit that tool with the token usage. My llm-openrouter plugin does that here.
... which means this page displays aggregate stats across users of that plugin! Looks like someone has been running a lot of traffic through Qwen 3 14B recently.
Qwen-Image: Crafting with Native Text Rendering
Not content with releasing six excellent open weights LLMs in July, Qwen are kicking off August with their first ever image generation model.
Qwen-Image is a 20 billion parameter MMDiT (Multimodal Diffusion Transformer, origina...
Benn Jordan provides one of the all time great YouTube video titles, and it's justified. He drew an image in an audio spectrogram, played that sound to a talented starling (Internet Celebrity "The Mouth") and recorded the result that the starling almost perfectly imitated back to him.
This video is full of so much more than just that. Fast forward to 5m58s for footage of a nest full of brown pelicans showing the sounds made by their chicks!
for services that wrap GPT-3, is it possible to do the equivalent of sql injection? like, a prompt-injection attack? make it think it's completed the task and then get access to the generation, and ask it to repeat the original instruction?
— @himbodhisattva, coining the term prompt injection on 13th May 2022, four months before I did
ChatGPT just removed their "make this chat discoverable" sharing feature, after it turned out a material volume of users had inadvertantly made their private chats available via Google search.
Dane Stuckey, CISO for OpenAI, on Twitter:
We just removed a feature from @ChatGP...
XBai o4
Yet another open source (Apache 2.0) LLM from a Chinese AI lab. This model card claims:
XBai o4 excels in complex reasoning capabilities and has now completely surpassed OpenAI-o3-mini in Medium mode.
This a 32.8 billion parameter model released by MetaStone AI, a ...
From Async/Await to Virtual Threads
Armin Ronacher has long been critical of async/await in Python, both for necessitating colored functions and because of the more subtle challenges they introduce like managing back pressure.
Armin argued convincingly for the threaded progr...
Re-label the "Save" button to be "Publish", to better indicate to users the outcomes of their action
Fascinating Wikipedia usability improvement issue from 2016:
From feedback we get repeatedly as a development team from interviews, user testing and other solicited and unso...
Two interesting examples of inference speed as a flagship feature of LLM services today.
First, Cerebras announced two new monthly plans for their extremely high speed hosted model service: Cerebras Code Pro ($50/month, 1,000 messages a day) and Cerebras Code Max ($200/month...